分布式服务跟踪Spring Cloud Sleuth使用详解2(与Zipkin整合)
Zipkin 是
Twitter 的一个开源项目,它基于
Google Dapper 实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。关于
Zipkin 更详细的介绍可以参考我之前写的文章(
点击查看)。 而
Spring Cloud Sleuth 在整合
Zipkin 时,不仅实现了以
HTTP 的方式收集跟踪信息,还实现了通过消息中间件来对跟踪信息进行异步收集的封装。下面分别对这两种方式进行介绍。
二、与 Zipkin 整合
1,以 Http 方式收集信息
(1)首先我们要启动个
Zipkin Server 服务,具体参考我之前写的文章:
(2)服务端搭建好后,我们还要对需要对具体应用做一些配置,以实现将跟踪信息输出到
Zipkin Server。这里我们对之前的
hello-service、
ribbon-consumer 两个微服务做个改造,在它们的
pom.xml 文件中引入
spring-cloud-sleuth-zipkin 依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
- 当然我也可以直接引入 spring-cloud-starter-zipkin 依赖,该依赖包含了 spring-cloud-starter-sleuth 和 spring-cloud-sleuth-zipkin 这两个依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
(3)接着在
hello-service 和
ribbon-consumer 的
application.properties 中增加
Zipkin Server 地址信息,同时指定通过
Http 方式将数据发送到
Zipkin Server:
spring.zipkin.base-url=http://192.168.60.133:9411 spring.zipkin.sender.type=web
2,通过消息中间件收集信息
(1)首先我们要启动个
Zipkin Server 服务,具体参考我之前写的文章,注意启动时要设置消息中间件(
RabbitMQ 或者
Kafka)的连接信息:
(2)服务端搭建好后,我们还要对需要对具体应用做一些配置,让应用客户端将跟踪信息输出到消息中间件上,而
Zipkin 服务端从消息中间件上异步地消费这些跟踪信息。
- 这里我们对之前的 hello-service、ribbon-consumer 两个微服务做个改造,在它们的 pom.xml 文件中增加引入 spring-cloud-sleuth-zipkin 和 spring-cloud-starter-stream-rabbit 依赖(如果使用的是 kafka 则引入 spring-cloud-starter-stream-kafka):
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
- 当然我也可以直接引入 spring-cloud-starter-zipkin 代替 spring-cloud-starter-sleuth 和 spring-cloud-sleuth-zipkin 这两个依赖,因为它包含了后面二者:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
(3)接着在
hello-service 和
ribbon-consumer 的
application.properties 中配置
RebbitMQ 的连接信息,同时指定将数据发送到
RabbitMQ(
Zipkin Server 默认的监听队列为名为
zipkin 的
Queue,数据通过
Direct 方式发送到该队列):
注意: 如果使用
Kafka 则将
spring.zipkin.sender.type 属性设置为
kafka,并配置
Kafka 连接信息。
spring.rabbitmq.host=192.168.60.133 spring.rabbitmq.port=5672 spring.rabbitmq.username=hangge spring.rabbitmq.password=123 spring.zipkin.sender.type=rabbit
附:运行测试
(1)首先我们多次请求
ribbon-consumer 应用的
/hello-consumer 接口,可以看到该应用控制台输出如下,当日志中出现跟踪信息最后一个值为
true 的时候,说明该跟踪信息会输出给
Zipkin Server: (1)因为
Sleuth 默认会使用
zipkin brave 的
ProbabilityBasedSampler 抽样策略,该策略以请求百分比的方式配置和收集跟踪信息,它的默认值为
0.1,代表收集
10% 的请求跟踪信息。也就是说默认有
10% 的几率将跟踪信息输出到
Zipkin Server。
(2)我们也可以根据情况修改采集率(比如测试时想让所有跟踪数据都能发送到
Zipkin Server),具体方法可以参考我的另一篇文章:

(2)此时我们可以去
Zipkin Server 的管理页面中选择合适的查询条件后,点击查询,就可以查询出刚才在日志中出现的跟踪信息了(也可以根据日志中的
Trace ID,在页面的右上角输入框中来搜索):

(3)点击下方
ribbon-consumer 端点的跟踪信息,我们还可以得到
Sleuth 跟踪到的详细信息,其中包括了我们关注的请求时间消耗等:

(4)点击这个
trace 中具体的
span 则可以在右侧显示该
span 的详情:

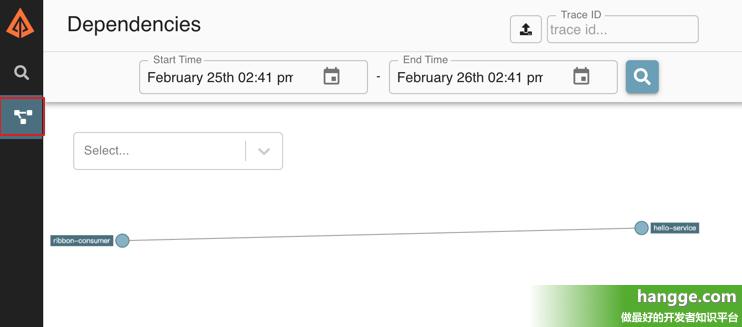
(5)点击导航栏的依赖分析按钮,还可以查看查看
Zipkin Server 根据跟踪信息分析生成的系统请求链路依赖关系图: