Kafka – 消费者的消费逻辑、消费顺序、及三种语义详解(至少、至多、仅一次)
一、Consumer 的消费逻辑
(1)正常情况下,
kafka 消费数据的流程是这样的:
- 先根据 group.id 指定的消费者组到 kafka 中查找之前保存的 offset 信息
- 如果查找到了,说明之前使用这个消费者组消费过数据,则根据之前保存的 offset 继续进行消费
- 如果没查找到(说明第一次消费),或者查找到了,但是查找到的那个 offset 对应的数据已经不存在了。此时会根据 auto.offset.reset 的值执行不同的消费逻辑。
提示:
kafka 默认只会保存
7 天的数据,超过时间数据会被删除。
(2)
auto.offset.reset 参数的值有三种:
- earliest:表示从最早的数据开始消费(从头消费)
- latest【默认】:表示从最新的数据开始消费
- none:如果根据指定的 group.id 没有找到之前消费的 offset 信息,就会抛异常(即查找到了,但是查找到的那个 offset 对应的数据已经不存在了)
(3)为什么新产生的数据我们是可以消费到的,但是之前的数据我们就无法消费?
- 当 auto.offset.reset 为默认的 latest 时,假设我们第一天使用一个消费者去消费了一条数据,然后就把消费者停掉了。
- 等了 7 天之后,我们又使用这个消费者去消费数据。这个时候,这个消费者启动的时候会到 kafka 里面查询它之前保存的 offset 信息
- 但是那个 offset 对应的数据已经被删了,所以此时再根据这个 offset 去消费是消费不到数据的
(4)总结,一般在实时计算的场景下,这个参数的值建议设置为
latest,消费最新的数据这个参数只有在消费者第一次消费数据,或者之前保存的
offset 信息已过期的情况下才会生效。
- 以 SpringBoot 项目为例,如果使用的是 kafka-clients 组件与 Kafka 进行集成,则在代码中通过如下方式设置:
Properties prop = new Properties();
//指定kafka的broker地址
prop.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
//指定key-value数据的序列化格式
prop.put("key.serializer", StringSerializer.class.getName());
prop.put("value.serializer", StringSerializer.class.getName());
// 设置 auto.offset.reset
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
//指定topic
String topic = "hello";
//创建kafka生产者
KafkaProducer <String, String> producer = new KafkaProducer<String,String>(prop);
//向topic中生产数据
producer.send(new ProducerRecord<String, String>(topic, "hello hangge.com"));
//关闭链接
producer.close();
- 如果我们使用的是 spring-kafka 这个组件,只要在项目 application.properties 文件中添加如下配置进行设置即可:
spring.kafka.consumer.auto-offset-reset=latest
二、Consumer 消费顺序
(1)当一个消费者消费一个
partition 时候,消费的数据顺序和此
partition 数据的生产顺序是一致的。
提示:
Kafka 使用
WAL(
write-ahead-log)日志来存储消息。每个分区都有一个对应的日志文件,新的消息会被追加到文件的末尾,而已经加入日志里的消息,就不会再被修改了。每个消息在分区日志里都有一个唯一的偏移量(
offset),用来标识消息在分区里的位置。因此
Kafka 可以保证同一分区内的消息顺序,但不保证不同分区之间的顺序。
(2)当一个消费者消费多个
partition 时候,消费者按照
partition 的顺序,首先消费一个
partition,当消费完一个
partition 最新的数据后再消费其它
partition 中的数据
总结:如果一个消费者消费多个
partiton,只能保证消费的数据顺序在一个
partition 内是有序的。也就是说消费
kafka 中的数据只能保证消费
partition 内的数据是有序的,多个
partition 之间是无序的。
三、针对消费者的三种语义
1,至少一次:at-least-once
(1)这种语义有可能会对数据重复处理
(2)实现至少一次消费语义的消费者也很简单:
- 设置 enable.auto.commit 为 false,禁用自动提交 offset
- 消息处理完之后手动调用函数 consumer.commitSync() 异步提交 offset
(3)这种方式有可能处理多次的场景是消费者的消息处理完并输出到结果库,但是
offset 还没提交,这个时候消费者挂掉了,再重启的时候会重新消费并处理消息,所以至少会处理一次。

2,至多一次:at-most-once
(1)这种语义有可能会丢失数据
(2)至多一次消费语义是
kafka 消费者的默认实现。配置这种消费者最简单的方式是
- enable.auto.commit 设置为 true。
- auto.commit.interval.ms 设置为一个较低的时间范围。
- 由于上面的配置,此时 kafka 会有一个独立的线程负责按照指定间隔提交 offset。
(3)这种方式消费者的
offset 已经提交,但是消息还在处理中(还没有处理完),这个时候程序挂了,导致数据没有被成功处理,再重启的时候会从上次提交的
offset 处消费,导致上次没有被成功处理的消息就丢失了。

3,仅一次:exactly-once
(1)这种语义可以保证数据只被消费处理一次。
(2)实现仅一次语义的思路如下:
- 将 enable.auto.commit 设置为 false,禁用自动提交 offset
- 使用 consumer.seek(topicPartition,offset) 来指定 offset
- 在处理消息的时候,要同时保存住每个消息的 offset。以原子事务的方式保存 offset 和处理的消息结果,这个时候相当于自己保存 offset 信息了,把 offset 和具体的数据绑定到一块,数据真正处理成功的时候才会保存 offset 信息,这样就可以保证数据仅被处理一次了。
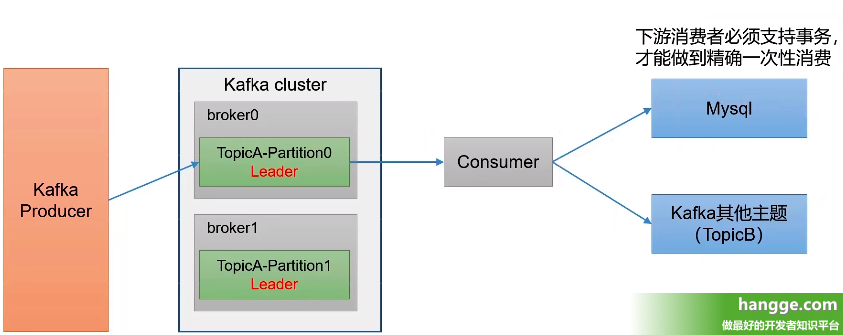
(3)比如下图,为了实现
Consumer 端的精准一次性消费,我们将
Kafka 的
offset 保存到支持事务的自定义介质中(比如
MySQL)。